nori 형태소 분석기 설치는 매우 간단합니다.
1. 현재 엘라스틱서치가 실행 중이라면 종료합니다.
2. 관리자모드로 명령프롬프트를 실행시킵니다.
3. 엘라스틱 서치 실행 경로 밑에 bin 경로로 이동합니다.
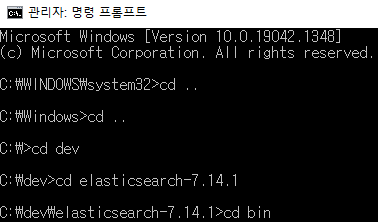
4. elasticsearch-plugin 모듈을 통하여 설치를 진행합니다.
C:\dev\elasticsearch-7.14.1\bin> elasticsearch-plugin install analysis-nori
설치가 완료되었습니다. 간단한 테스트를 통하여 정상적으로 설치되었는지 확인할 수 있습니다.
5. 테스트
저는 postman 프로그램으로 요청하여 테스트를 해보겠습니다. 먼저 standard tokenizer를 통하여 기존 분석 값을 확인합니다.
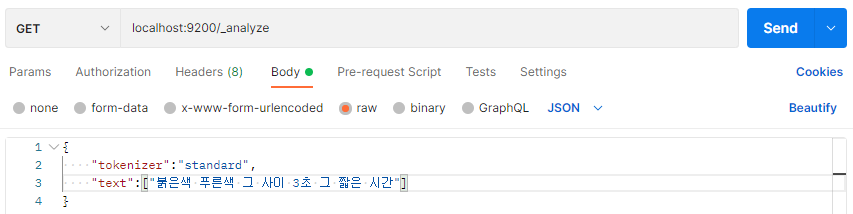
결과 확인
{
"tokens": [
{
"token": "붉은색",
"start_offset": 0,
"end_offset": 3,
"type": "<HANGUL>",
"position": 0
},
{
"token": "푸른색",
"start_offset": 4,
"end_offset": 7,
"type": "<HANGUL>",
"position": 1
},
{
"token": "그",
"start_offset": 8,
"end_offset": 9,
"type": "<HANGUL>",
"position": 2
},
{
"token": "사이",
"start_offset": 10,
"end_offset": 12,
"type": "<HANGUL>",
"position": 3
},
{
"token": "3초",
"start_offset": 13,
"end_offset": 15,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "그",
"start_offset": 16,
"end_offset": 17,
"type": "<HANGUL>",
"position": 5
},
{
"token": "짧은",
"start_offset": 18,
"end_offset": 20,
"type": "<HANGUL>",
"position": 6
},
{
"token": "시간",
"start_offset": 21,
"end_offset": 23,
"type": "<HANGUL>",
"position": 7
}
]
}standard tokenizer는 띄워쓰기 기준으로 분석을 하는 모습을 확인할 수 있습니다. 이제 nori tokenizer로 분석한 결과를 확인해 보겠습니다.

결과 확인
{
"tokens": [
{
"token": "붉은",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "색",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 1
},
{
"token": "푸른",
"start_offset": 4,
"end_offset": 6,
"type": "word",
"position": 2
},
{
"token": "색",
"start_offset": 6,
"end_offset": 7,
"type": "word",
"position": 3
},
{
"token": "그",
"start_offset": 8,
"end_offset": 9,
"type": "word",
"position": 4
},
{
"token": "사이",
"start_offset": 10,
"end_offset": 12,
"type": "word",
"position": 5
},
{
"token": "3",
"start_offset": 13,
"end_offset": 14,
"type": "word",
"position": 6
},
{
"token": "초",
"start_offset": 14,
"end_offset": 15,
"type": "word",
"position": 7
},
{
"token": "그",
"start_offset": 16,
"end_offset": 17,
"type": "word",
"position": 8
},
{
"token": "짧",
"start_offset": 18,
"end_offset": 19,
"type": "word",
"position": 9
},
{
"token": "은",
"start_offset": 19,
"end_offset": 20,
"type": "word",
"position": 10
},
{
"token": "시간",
"start_offset": 21,
"end_offset": 23,
"type": "word",
"position": 11
}
]
}standard tokenizer와 다른 결과가 나왔습니다.


